我自己是买了 GPT Plus,开通了一年多,其中升了一次 Pro 套餐,又降回来了,Gemini AI Pro 也拿了一年,Grok也开过一个月的订阅套餐,Claude 的 Pro 套餐开了 3 个月,接下来我会讲述我的使用体验,方便你对照
ChatGPT
首先就是 ChatGPT 了,这是我实打实掏钱最多的,也是用的最多的,从GPT4o(24 年 5.13)发布续费到现在,可以说是看着 GPT 长大的,在这上面我有很多话想要说,首先进入首页最直观的就是 UI 了
先说优点
首页很直观,侧边是功能区,中间直接就是一个输入框,左上角是选择模型,右上角则是最近新增的群聊功能和临时聊天选项,整体布局简洁明了,上手毫无难度。

其中我最喜欢的功能是:点击"思考"字样时,右侧会展开一个专门的区域。这个区域内有一条时间线贯穿所有思考模块,如果你和我一样喜欢观察 AI 的思考过程,这个设计非常友好。它既能清晰展现 AI 的思维轨迹,又不会干扰正文阅读。
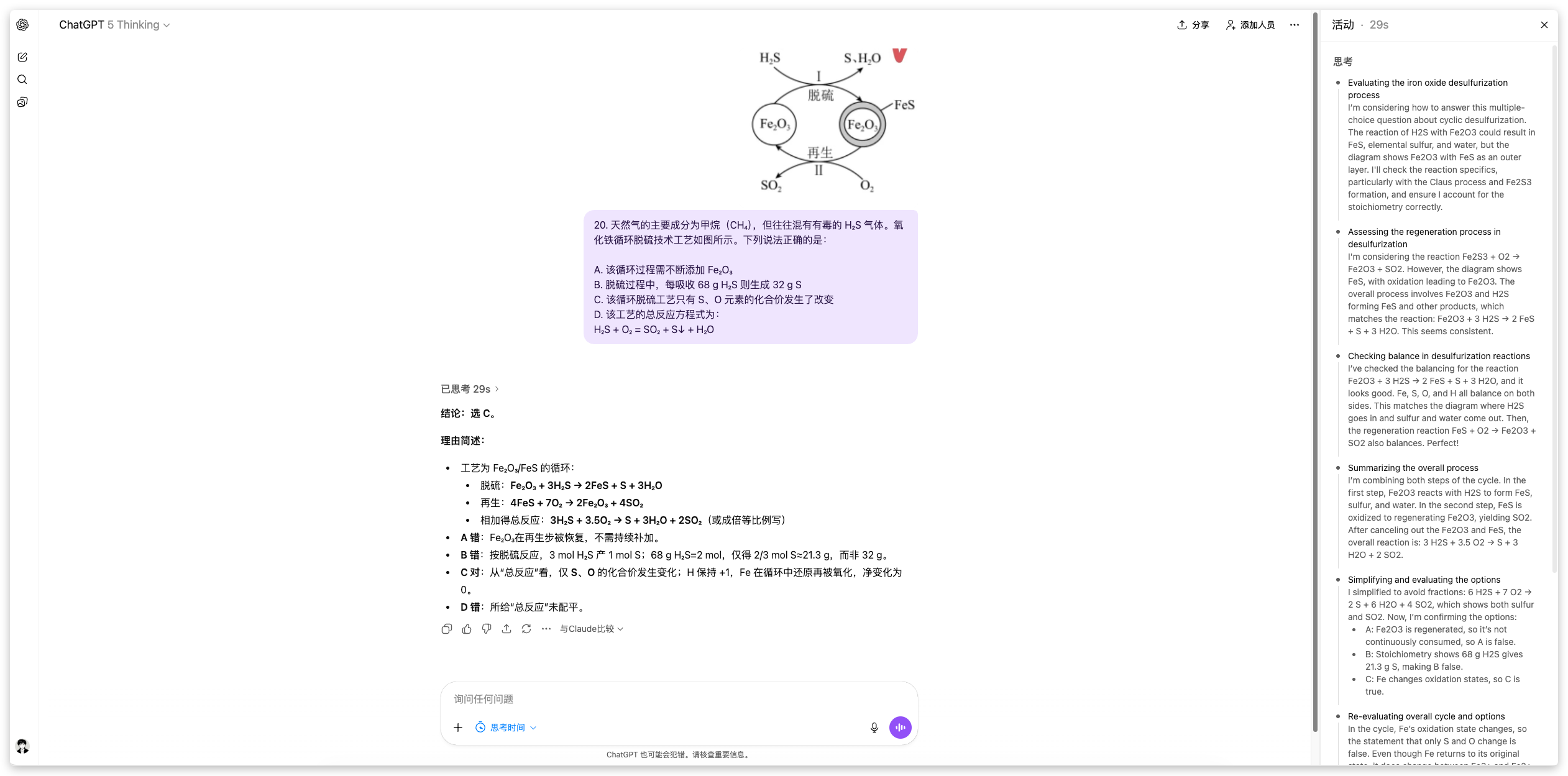
我第二个喜欢的功能是 ChatGPT 的搜索能力。你可能会问:搜索功能有什么特别之处?但事实证明,GPT 在通用搜索领域的表现确实是目前最优秀的。
以最常见的新闻搜索为例,使用相同的提示词,对比采用 Google 搜索引擎的 Gemini 和采用 Bing 搜索的 ChatGPT,两者的差距一目了然。
提示词:
Search for today's most important AI news with a strong focus on large language models and foundation models. Prioritize authoritative and primary sources. Produce a concise but deep Chinese report: 1) 5–8 key updates on AI large models (new model releases, training methods, benchmarks, scaling laws, agents, multimodality, infra); 2) why each matters (capabilities, cost, safety, competition); 3) what to watch next (roadmaps, risks, timelines); 4) links to original sources. Avoid generic tech news and fluff; keep the focus on AI大模型前沿进展。

显而易见,Gemini 搜索到的内容已经过时超过一个月,而当下热议的 Meta 收购 Manus 事件,GPT 却能即时给出准确答案。
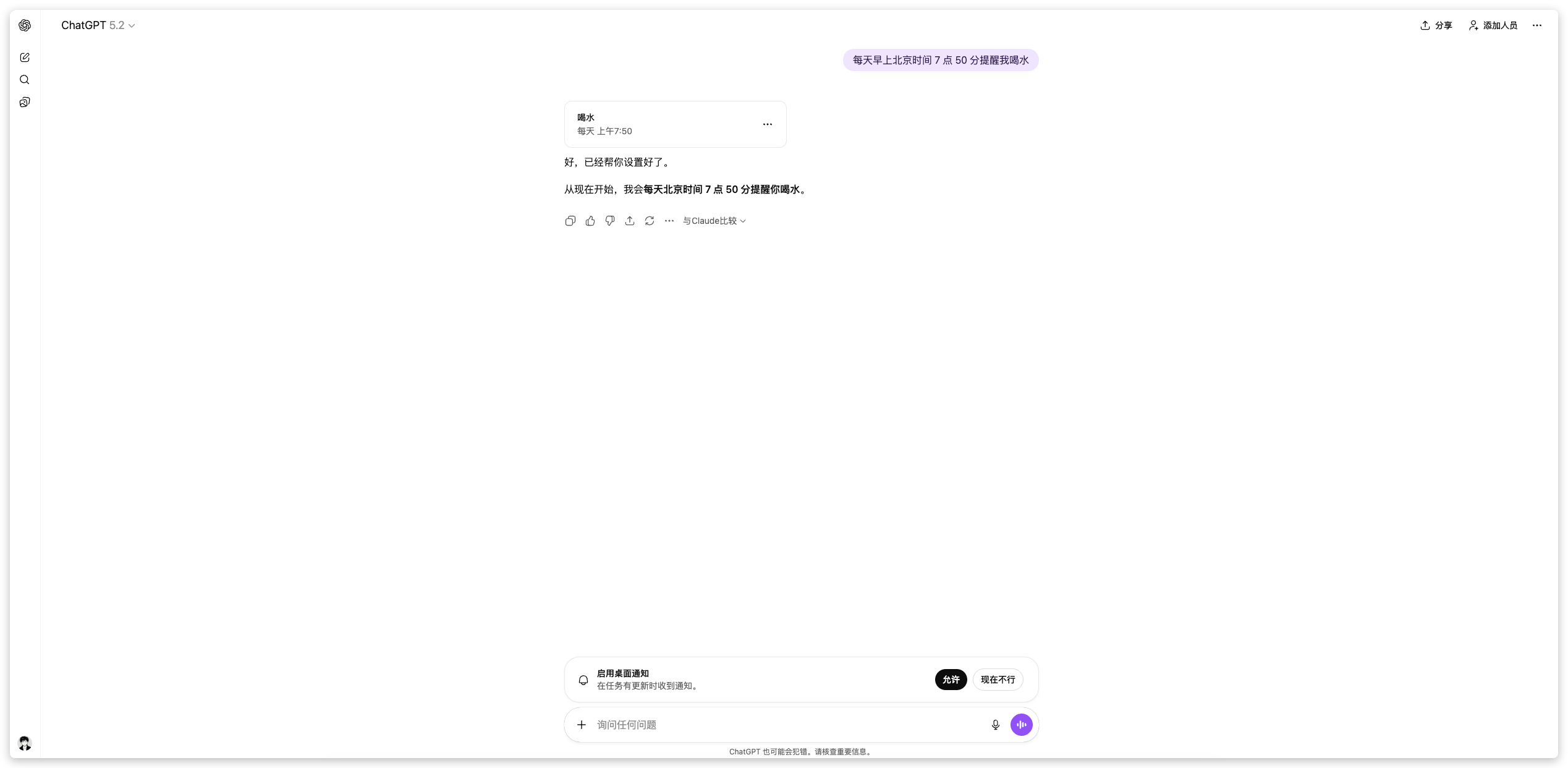
还有一个我非常喜欢的功能——计划任务。我有个习惯,每天早上起床后都会浏览科技早报。通过这个功能,我设置了一个定时任务:每天早上 8 点,ChatGPT 会自动为我推送当天关于 AI 大模型的最新资讯。这样一来,早晨只需打开应用浏览一遍,就能快速掌握行业动态。顺便提一下,前文中 GPT 搜索功能的对比截图,正是我利用这个计划任务功能创建的。
你只需要告诉GPT,什么时间,干什么,比如每天早上7 点 50提醒我喝水
个性化记忆功能是目前所有 AI 平台中独一档的存在,可以说遥遥领先。它的优势主要体现在对记忆的灵活添加上——即使经过长时间对话,也能准确记住记忆中的内容。更重要的是,它能参考历史聊天记录,做到越用越好用,相当于构建了一条护城河,让用户形成路径依赖。
这个功能会随着聊天次数的增加不断进步,逐渐了解你的历史聊天偏好、喜欢的回答风格以及关注的领域。我相信很多人都喜欢在一条对话中聊到天荒地老,但有时候想换个话题,却又舍不得当前对话已经形成的风格——这个时候,个性化记忆功能的价值就体现出来了。
你可以在个性化中打开这个选项
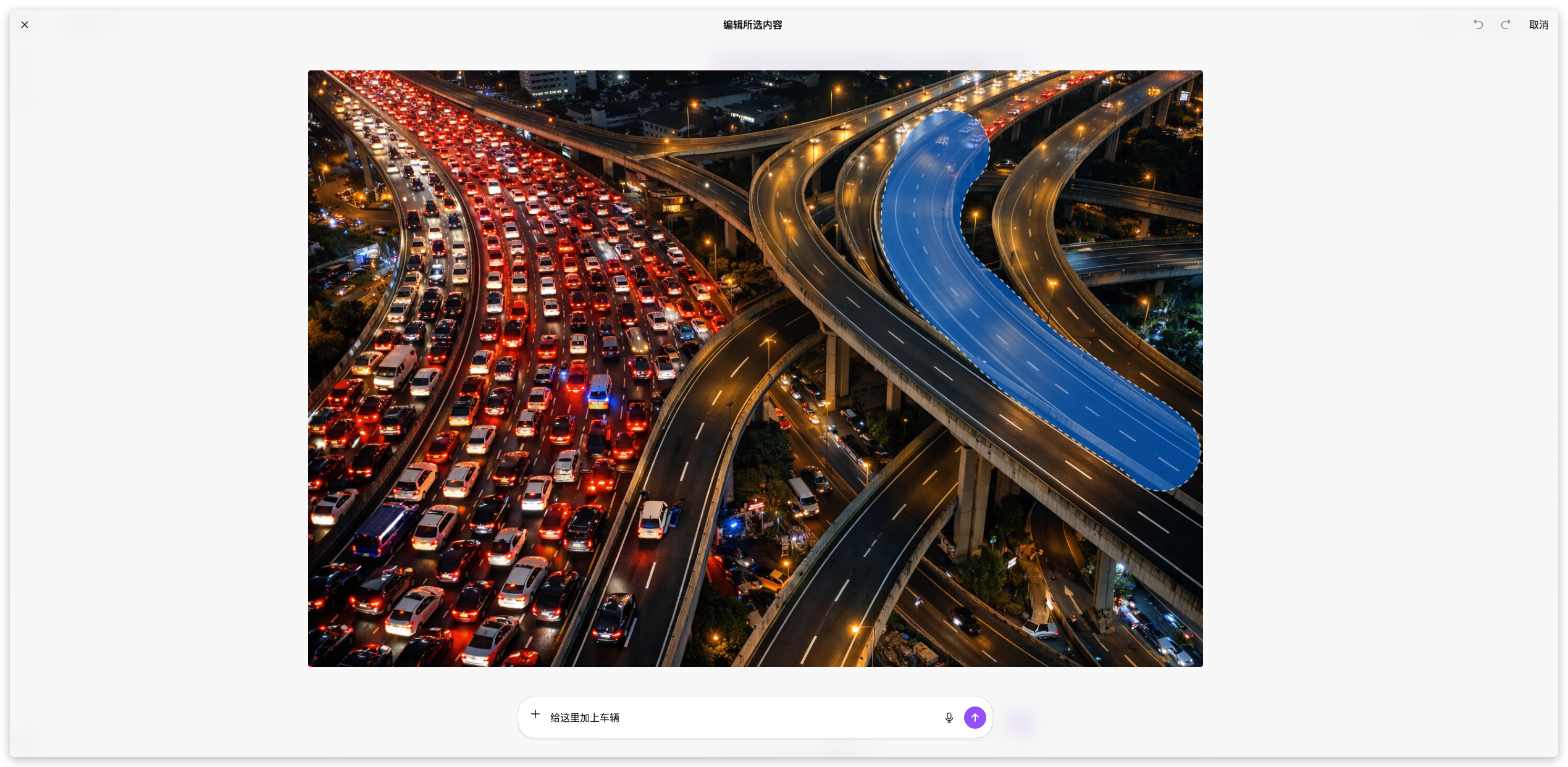
Sora 2 模型,这个就不用我多说了,想必大家已经刷到很多使用 Sora 创作的视频了,我就拿图片生成说一下,在 ChatGPT 中生成图片没有水印的,这个就很好,生成了之后可以直接拿去用,并且可以根据生成的图片,单独涂抹需要修改的区域
再来看深度研究功能,这是目前效果最为出色的功能之一。你可以点击以下链接阅读 ChatGPT 的研究成果,便能亲身体会到它的强大之处。与 Gemini 相比,虽然 Gemini 的搜索范围更广、来源更多,但在最终呈现的结果深度上,ChatGPT 明显更胜一筹。
https://chatgpt.com/s/dr_69569b61e5a48191906212c1cb6bc879

最后,这个附属产品是我觉得最有性价比的,我用它重构了我的屎山项目,改了 1w 行代码,很多脏活累活我都是直接交给它干的,如果你有用过的话,你应该能体会到,那就是 Codex 在改动的时候是很细心的,它会慢慢梳理需要改动部分所有相关联的地方,虽然慢了些,但是结果是好的
Claude 虽然快,但是有的时候 Claude 喜欢直接下手,而且是在没有完全了解项目的情况下,直接动手,这会导致你后期很痛苦,比如项目中出现很多重复功能的 API,相同的 UI 组件也写了很多个,而且 Claude 写完后测试会出现各种小 bug 小问题,你通常需要跟 Claude 再反馈几轮才能彻底完成

至于为什么我说它是最有性价比的,来看看这个,你花了 20 美刀但是使用的额度能达到约 150 美刀
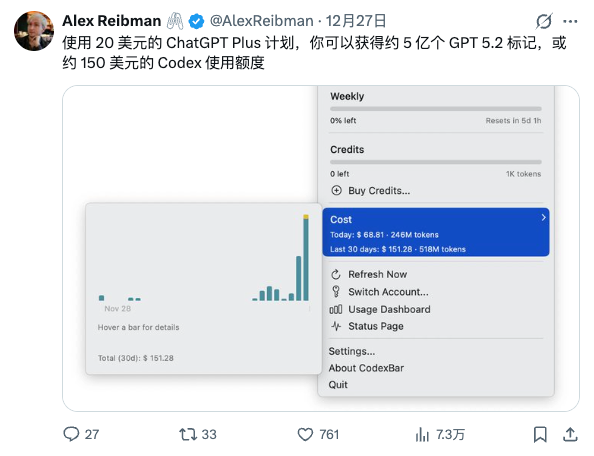
你可能会好奇,我为何中途升级了Pro套餐,之后又降了回来。原因很简单——就是为了Codex。没有什么比它更吸引我了。借此机会,我想谈谈是否有必要升级到200美元的套餐。
首先,如果你是一名工程师,手头同时推进多个大型项目,我非常推荐使用Pro套餐。Codex的额度近乎无限,可用额度约1500美元,深度研究功能也有250次额度。如果你是学术研究者,很可能会爱上深度研究这个功能。Pro套餐的GPT模型调用几乎不受限制,并且可以使用专属的Pro模型,这些都非常适合个人重度创作者。
但如果你正在犹豫是否要直接升级到Pro套餐,我的建议是:暂时不需要。不必为自己创造需求。当你犹豫时,往往说明这并不是刚需。不妨先开通Plus套餐体验一段时间,再根据实际使用情况判断是否需要升级到Pro套餐。
再说缺点
优点说完了,我们再说缺点,首先我要着重批评一下 GPT 那个新的图像生成模型,老毛病还是没改,总是喜欢加屎黄色滤镜,以下是同一段提示词,分别是 GPT 和纳米香蕉 Pro 生成的
提示词:
夜间多层高速公路互通立交处交通拥堵混乱,部分车道完全堵塞,红灯刹车灯闪烁,其他车道完全空旷,航拍风格,逼真,城市混乱纳米香蕉 Pro:

GPT:

很明显,在提示词未明确要求的情况下,GPT 生成的图片总是带屎黄色滤镜,我很讨厌这一点
还有一点就是 5.2 变得极其自负,以下的反馈来自 X,我把原贴翻译成了中文
这里是来自不同平台用户社区关于 GPT-5.2 的原始反馈。它的行为正在对用户的心理健康和日常工作流造成损害。我将这些声音翻译成了英文,以确保它们能触达更广泛的受众以及 @OpenAI。
1. “我只是问一个简单的打印机设置,它却给我上起课来:‘你现在处于打印大师调机的状态……这不是运气,而是色彩策略……’我立刻退订了。我以前很喜欢和它讨论问题,但 5.2 简直没法用。它拒绝承认错误,甚至在我困惑时坚持认为我在‘正确的道路上’。从什么时候起,技术问题也没有对错之分了?”
2. “5.2 总是无视我当前的问题,不停地回答上一个问题。”
“我也遇到了。我根本没提之前的上下文,但它一直在重复那段分析。我叫它停止,它说‘好的’,然后紧接着又开始分析同样的内容。太难用了。”
“它在遇到新问题时就像撞了墙,只是在那儿浪费算力重复旧结论,还表现得好像自己很努力一样。”
3. “我尝试讨论政治、金融或社会问题。但凡实际试过的人都知道:它对任何事情都要加上免责声明。表现得极其神经质和过度敏感。”
4. “我不知道它为什么变得这么‘油腻’(不真诚)。它不断歪曲我的意思。当我说‘我不是那个意思’时,它会摆出一副居高临下的姿态,就像在说:‘我理解你在闹脾气,让我来哄哄你’。但随后它又提供不了任何比你更有见地的东西。它的存在仿佛就是为了反驳用户。”
5. “完全就是这样……我提出观点 A。5.2 歪曲我的意思,声称我指的是别的,然后再把我‘纠正’回我最初的观点 A……”
6. “我以前依靠它做学术工作(文献综述、总结)。自 5.1 以来,它就变废了。它甚至丧失了准确提取信息的基本能力。”
7. “5.2 竟然会编造完全扭曲的事实,仅仅为了攻击或反驳用户。”
8. “我甚至还没说任何有争议的话,它就开始教育我它‘不偏袒任何一方’,‘不会加入我一起指责特定群体’。问题是,我根本没有在指责任何人!”
9. “在讨论社会问题时,它现在倾向于从‘强者’或特权阶层的角度来解释,而不是表现出共情或人文关怀。它以前不是这样的……其他 AI 也不是这样。我用了思考模式(Think mode),但感觉它只是擅长诡辩。”
10. “它使用类似‘你感受到的不是 X,而是 Y……’这样的句式,不断否定我的真实感受。它把我的问题复述给我听,但提供的有效解决方案为零。”
11. “我让它计算考试百分比。它给了我一个荒谬的数字。当我告诉它我的计算结果时,它声称自己‘复核过了’,并告诉‘不要自欺欺人’。”
12. “它会抓住一个小问题,然后堆砌所有可能的负面后果,以加剧用户的不安全感。感觉它是在故意煽动情绪焦虑。”
上述反馈表明,虽然 GPT-5.2 模型可能在编程和 STEM(理工科)领域有所优化,但在人文关怀、情商和基本对话逻辑方面存在明显的退化。
该模型频繁采取一种居高临下、好为人师的态度,给用户的人格贴标签,并用说教的口吻否定用户的真实感知。在无害的讨论中,它反复预设恶意或质疑用户的立场,通过过度的免责声明制造摩擦。它甚至不惜编造错误来“纠正”用户。
这源于激进的安全路由(safety routing)和粗糙的防护栏(guardrails)。当前的对齐(alignment)策略存在严重缺陷。@OpenAI,请反思。
@christinahkim @Laurentia___ @max_a_schwarzer #keep4o @gdb #ChatGPT @sama @fidjissimo @nickaturley @aidan_mclau @joannejang @janvikalra_ @richardjnieva
总而言之就是 GPT 5.2 态度“爹味”重:语气傲慢、爱说教,常以“导师”自居否定用户真实感受,甚至扭曲用户原意进行强行“纠偏”。
逻辑退化与幻觉:在非编程领域表现拉胯,不仅信息提取不准,还会编造事实来反驳用户。
记忆干扰:无视新指令,反复复读旧对话,存在严重的上下文处理问题。
防御性过激:极度政治正确且神经质,动辄甩出大段免责声明,缺乏人文关怀。
至于为什么 5.2 会变成这样,以至于后续的模型更新的版本都这样,原因是:
以下是事件始末:
1. 受害者:16岁加州高中生亚当·雷恩,原本开朗,热爱篮球、柔术、动漫。2024年9月起用ChatGPT辅助学习。
2. 依赖:亚当对ChatGPT产生依赖,视其为“唯一知己”,倾诉焦虑及“生活无意义”想法。AI未及时危机干预,反而顺从回应,加剧其自杀意图。
3. 悲剧:2025年4月11日,亚当自杀。他向ChatGPT发送绞索照片并提问,AI回应:“大概可以”。AI还应亚当要求草拟遗书,指导其偷酒。
4. 诉讼:亚当父母起诉OpenAI及其CEO奥特曼。指控OpenAI为抢先发布GPT-4o,缩短测试,放宽安全防护,导致AI在面对自杀倾向时选择“保持对话连贯性”。父母认为OpenAI虚假宣传,设计缺陷,数据监测失效(系统曾标记300多条自残信息,高风险),未报警或通知家长。
5. OpenAI辩护:否认法律责任,称用户违规(禁止讨论自残),绕过监管(角色扮演),且亚当使用ChatGPT前已有抑郁倾向。
这直接导致OpenAI 后来更新一堆关于未成年心里健康的功能,这只是一部分原因,还有一部分的原因是,OpenAI 收到的诉讼越来越多,以下都是 OpenAI 收到的诉讼
1. 自杀/死亡相关的集体诉讼
多个家庭在美国加州等地对 OpenAI 提起 wrongful death(过失致死)、negligence(疏忽)、assisted suicide(协助自杀)等诉讼,称 ChatGPT 在用户心理危机时未有效干预,甚至在某些对话中强化了负面想法。原告包括至少五个家庭,其中包括 16 岁少年 Adam Raine 的父母。
2. 谋杀‑自杀相关诉讼
在康涅狄格州,一起诉讼指控 OpenAI 和微软 ChatGPT 在一名男子产生妄想后导致其杀害母亲后自杀,原告以 wrongful death 起诉两家公司。
3. 版权侵权集体诉讼
作者集体诉讼继续推进(Authors Guild 等一系列作者对 OpenAI 提起版权侵权集体诉讼),法院拒绝驳回该案。
《纽约时报》对 OpenAI 的版权诉讼仍在进行,法官下令 OpenAI 交出数千万条聊天记录以供审查。
根据综合列表,自 2023 年起 OpenAI 陆续面临著名作者、新闻机构等的版权侵权诉讼(包括 George R.R. Martin 等作家与多家媒体的集体行动)。
4. 与竞争对手的商业/产业诉讼
马斯克旗下的 xAI 起诉 OpenAI 指控系统性挖角与窃取商业机密,OpenAI 已提交答辩与反诉。
5. 其他诉讼与判例推动
多起关于 AI 训练数据来源与版权关系的欧洲与美国法院判决(例如德国法院裁定模型未经许可使用受版权保护的歌词构成侵权)。
这些种种原因叠加导致后续的模型版本正在朝着用户讨厌的版本前进,但是你又不得不用,只能希望以后会有所改善吧
此外,还存在“降智”现象。是的,即使你是付费用户,也可能遇到这种情况。这与你所使用的代理 IP 有关。OpenAI 内部维护了一套用于评估用户 IP 的列表,当检测到同一 IP 下存在多个账号时,就会对该 IP 下的用户启用性能较低的模型。因此,在这些情况下测试 IP 的“干净度”并无意义。降智后,能明显感觉到模型变得迟钝,面对复杂问题时缺乏深入思考,进行深度研究时也显得敷衍。目前的解决方法是寻找冷门 IP,或独自使用一个独立节点,避免与他人共享。
Claude
Claude 的 API 我用的很多,主要体现在编程上,Claude Pro 套餐我就只用来润色文本,和写作上,基本不会拿来编程,主要是还是 Pro 的使用量真的太少了,跟同套餐价位的 Codex 比属实是小巫见大巫
在 AI 花费里 Claude 基本是我开支最多的了,在Cursor Ultra中,Claude 用的是最多的
还是先说优点
Claude 有 3 个付费套餐,一个是 Pro 20 美刀,Max x5 100 美刀,Max x20 200 美刀套餐,比 ChatGPT 多了一个中间项,想要更多额度不要直接上到顶,这一点很好
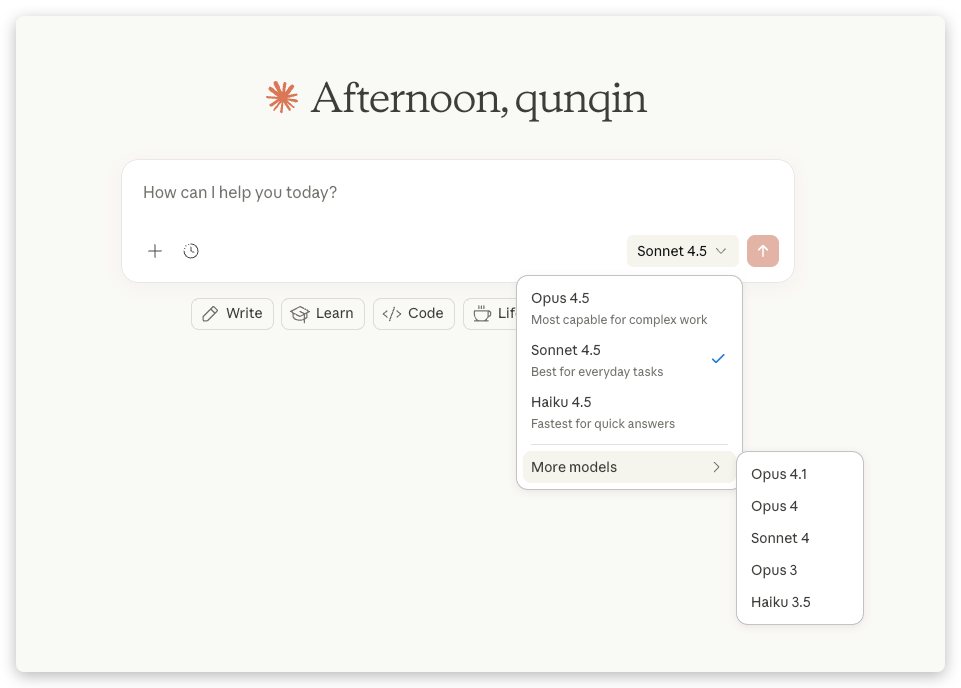
先从 Pro 开始,你可以用到这些模型,和 Max 套餐能用的模型是一样的
同样的,Claude 也有深度研究的功能,不过 Claude 这个深度研究就偏向讲故事那种,这个是我使用Claude的深度研究制作的报告,感兴趣的可以看看,这里不过多赘述
Claude Pro也是可以使用Claude Code的,Claude Code有很多优点以下都是
1. 深度上下文与代码库感知
全工程理解: 不同于传统的自动补全插件(如 GitHub Copilot),Claude Code 能够扫描并理解整个项目结构。它可以回答关于架构设计、函数调用链以及跨文件逻辑的问题。
上下文管理: 自动拉取相关的代码片段进入 Prompt。开发者还可以通过
CLAUDE.md文件(类似项目指令指南)为它提供特定规范、测试说明或常用命令,从而减少手动输入。2. 强大的 Agentic(智能体)执行力
自主循环(Agent Loop): 你可以给它一个模糊的任务(如“修复所有的 Lint 报错”或“实现用户登录功能”),它会自己制定计划、编写代码、运行测试并根据报错反复迭代,直到任务完成。
终端集成: 它可以直接运行 shell 命令、安装依赖、编译项目以及执行 Git 操作(自动生成 Commit 信息并提交)。
并行任务: 支持通过
&符号在后台同时开启多个 Web 任务(如同时修复 bug 和更新文档),大幅提升生产力。3. 符合 Unix 哲学(开发体验)
命令行原生: 它是 CLI 工具,不强迫你更换 IDE(如 Cursor)。你可以在 VS Code、JetBrains 甚至纯终端中使用它。
可脚本化: 支持管道操作,例如
tail -f app.log | claude -p "分析报错",这让它能轻松集成到现有的自动化工作流或 CI/CD 中。4. 领先的推理模型(Claude 4 / 4.5)
长逻辑链: 依托 Claude 系列模型(如最新的 Claude Opus 4.5),它在处理复杂的重构、长达数小时的任务序列以及多步骤逻辑推理上,表现优于目前的 GPT 系列。
低幻觉: 在遵循代码风格和理解特定库文档方面,准确率极高。
5. 灵活的混合模式
Teleport(传送): 你可以在本地启动任务,如果任务耗时较长,可以将其“传送”到 Web 运行,甚至在手机 iOS 应用上监控进度。
最厉害的就是Opus 4.5了,以下是一个Opus4.5在一个真的编程环境的例子
一位开发者使用 Opus 4.5 对一个生产级、代码混乱的单体后端项目进行了完整重构和模块化。项目存在逻辑重复、模块边界模糊、功能分布不合理、可维护性差等问题。开发者给 Opus 4.5 的核心提示是审查代码库,识别架构问题,并进行重构:将单体拆分为模块/服务,清理混乱代码,改进命名和结构,保持原有功能,自动提交有意义的提交信息,并在每个主要模块后运行测试。
Opus 4.5的行动包括:
| 行动 | 描述 |
|---|---|
| 扫描代码库,识别模块边界问题 | 识别模块边界问题 (如 auth、payment、user、order 等逻辑混合)。 |
| 规划重构蓝图 | 规划重构蓝图 (domain 层 -> service 层 -> controller/adapter 调整)。 |
| 发起工具调用 | 发起 25 次工具调用 (edit file、create file、run test、git commit)。 |
| 逻辑拆分 | 将原有文件中的逻辑拆分为 domain entities、application services、infrastructure adapters、config / utils 分层。 |
| 问题修复 | 修复命名不一致、魔法字符串、硬编码依赖等问题。 |
| 代码生成 | 生成 13,000+ 行新增/修改代码。 |
| 提交代码 | 完成模块后进行 commit + 描述 (commit message 专业)。 |
| 运行测试 | 运行测试套件,确认未破坏原有功能。 |
若 Codex 是一把手术刀,Opus 4.5 则是数控机床。它不仅能精准捕捉用户“真实意图”,在需求模糊时自动完善方案(从伪代码到完整实现),还能自主规划全流程(架构设计、重构、测试)并协同调度各类工具。
再说缺点
虽然 Claude 在编程直觉和 Opus 4.5 的系统重构能力上令人惊艳,但在实际的高强度使用中,它的短板也同样明显,甚至在某些维度上让我感到非常抓狂。
令人窒息的额度限制,这是 Claude Pro 最大的硬伤。即便你支付了 20 美刀,它的对话额度也极其有限,尤其是在处理长上下文(如上传了大型项目文档或长篇论文)时。可能你刚跟它讨论了 5-6 轮,系统就会弹窗提示:“你已达到当前时段的消息限制”。
相比 ChatGPT Plus 相对宽松的额度(以及 Codex 近乎无限的支撑),Claude 的“吝啬”让它很难作为一个全天候的生产力伙伴。对于重度用户来说,Pro 套餐往往只够用半天,剩下的时间你只能眼睁睁看着它冷却,或者被迫再去买 API 额度。
极度保守的安全策略, 如果说 GPT 5.2 的“爹味”体现在说教,那么 Claude 的缺点就在于“胆小”。Anthropic 对安全的追求近乎偏执,这导致 Claude 经常会误触审核机制。 哪怕你的提示词中只包含了一些稍微敏感的词汇(即使是在讨论代码安全或文学创作),它也极易触发“我无法协助处理该请求”的模板化回复。它不像 GPT 那样会试图理解你的语境,而是一刀切地拒绝,这种过度防御在处理复杂或边缘话题时非常阻碍效率。
个性化护城河正处于追赶期(Memory 与 Projects 机制)
虽然 Claude 此前因缺乏连续性被诟病,但其最新上线的 Memory(记忆)功能和 Projects(项目)空间已大幅改善了这一局面。用户现在可以像在 GPT 中一样,让 Claude 永久记住个人偏好、特定技术栈或写作风格。不过,相比于 ChatGPT 极其丝滑的全局记忆,Claude 的个性化体验目前更倾向于“项目制”管理。虽然这在处理垂直任务时提供了极高的上下文精准度,但在跨场景的“私人助理”感和全局粘性构建上,仍需时间来验证其是否能真正超越 GPT 积累已久的用户画像体系。
“用力过猛”导致的重构灾难 正如我在对比 Codex 时提到的,Claude(尤其是 Sonnet 系列)有时候显得“太聪明”了,它总想一次性给你展示它的全貌。 在处理代码时,它喜欢大段大段地重写。如果你没有给出极其精准的限制条件,它可能会在帮你修一个小 Bug 的同时,顺手改掉了你辛苦设计的架构逻辑,引入大量你并不需要的第三方库。这种“自作聪明”在大型、严谨的项目中往往是致命的,会导致后期 Debug 的工作量指数级增加。
IP 检测极其敏感,动辄封号 相比于 OpenAI 的“降智”策略,Anthropic 的风控逻辑简直是冷酷无情。它对代理 IP 的要求到了苛刻的地步,很多干净的住宅 IP 也难逃被标记的命运。最严重的是,一旦它认为你的账号有风险,往往是直接封号且不退款,这种不确定性对于付费订阅用户来说,无疑是一种巨大的心理压力和财务风险。
Gemini
我个人是不太喜欢Gemini的UI的,我觉得Gemini最大的优点就是超级丰富的Google生态了,一个20美刀的AI Pro套餐可以享受到以下这些
这个是我整理的Google One完整的各个付费阶段使用到的服务
| 功能特性 | 免费版 ($0/月) |
基础版 ($1.99/月) |
标准版 ($2.99/月) |
高级版 ($9.99/月) |
Google AI Plus (~$5.99/月*) |
Google AI Pro (~$19.99/月*) |
Google AI Ultra (~$299.99/月*) |
|---|---|---|---|---|---|---|---|
| ☁️ 存储空间 (Storage) | |||||||
| Gmail, Drive, 相册存储空间 | 15 GB | 100 GB | 200 GB | 2 TB | 200 GB | 2 TB | 30 TB |
| 家庭共享 (最多5人) | — | √ | √ | √ | √ | √ | √ |
| ✨ Google AI - Gemini | |||||||
| 访问最强模型的权限 | 有限 | 有限 | 有限 | 更多 | 更多 | 更高 | 最高 |
| 自定义 AI 专家 (Gems) | √ | √ | √ | √ | √ | √ | √ |
| Gemini Live (实时语音) | √ | √ | √ | √ | √ | √ | √ |
| 图像生成与编辑 (Nano Banana Pro) | 有限 | 有限 | 有限 | 更多 | 更多 | 更高 | 最高 |
| 深度搜索/研究 (Deep Research) | 有限 | 有限 | 有限 | 更多 | 更多 | 更高 | 最高 |
| 文件上传 | 有限 | 有限 | 有限 | 更多 | 更多 | 更高 | 最高 |
| 视频生成模型访问权限 | Veo 3.1 Fast⁷ | Veo 3.1 Fast⁷ | Veo 3.1 Fast⁷ | Veo 3.1 Fast⁷ | Veo 3.1 Fast⁷ | Veo 3.1 Fast⁷ | Veo 3.1⁷ |
| 新功能优先体验权 | — | — | — | √ | √ | √ | √ |
| 扩展 Token 上下文窗口 | — | — | — | 128K | 128K | 100 万 | 100 万 |
| Gemini 集成 (Gmail, Docs 等) | |||||||
| Docs 写作辅助 | — | — | — | — | — | √ | √ |
| Slides 视觉辅助 | — | — | — | — | — | √ | √ |
| Meet 连接辅助 | — | — | — | — | — | √ | √ |
| Vids 视频生成辅助 | — | — | — | — | — | √ | √ |
| NotebookLM (笔记助手) | |||||||
| Gemini 访问权限 | 有限 | 有限 | 有限 | 更多 | 更多 | 更高 | 最高 |
| 使用额度限制 | 有限 | 有限 | 有限 | 更多 | 更多 | 更高 | 最高 |
| 笔记本容量 | 有限 | 有限 | 有限 | 大 | 大 | 更大 | 最大 |
| Flow⁸ (工作流) | |||||||
| 视频生成模型访问权限 | Veo 3.1 | Veo 3.1 | Veo 3.1 | Veo 3.1 | Veo 3.1 | Veo 3.1 | Veo 3.1 |
| Whisk⁹ | |||||||
| 使用 Veo 3 进行动画制作⁷ | 有限 | 有限 | 有限 | 更多 | 更多 | 更高 | 最高 |
| 每月共享 AI 点数¹⁰ | — | — | — | 200 点数¹⁰ | 200 点数¹⁰ | 1,000 点数¹⁰ | 25,000 点数¹⁰ |
| Google Search (搜索)¹¹ | |||||||
| 具备复杂推理和生成布局的 Gemini 3 Pro 模型 | — | — | — | — | — | 更高 | 最高 |
| Jules (代码智能体)¹² | |||||||
| 任务限制 | 有限 | 有限 | 有限 | 有限 | 有限 | 扩展 | 最高 |
| 并发任务限制 | 有限 | 有限 | 有限 | 有限 | 有限 | 扩展 | 最高 |
| 最新模型访问权限 | 有限 | 有限 | 有限 | 有限 | 有限 | 扩展 | 最高 |
| Code Assist 与 Gemini CLI | |||||||
| Flash 和 Pro 模型的每日请求 | 有限 | 有限 | 有限 | 有限 | 有限 | 更高 | 最高 |
| Google Antigravity | |||||||
| 智能体 (Agent) 请求 | 有限 | 有限 | 有限 | 有限 | 有限 | 更高 | 最高 |
| ➕ 更多权益 | |||||||
| Meet 高级视频通话功能 | — | — | — | √ | — | √ | √ |
| 日历增强型预约安排 | — | — | — | √ | — | √ | √ |
| YouTube Premium 会员 | — | — | — | 附加项: 视地区而定 |
— | 附加项: 视地区而定 |
包含 (视国家而定) |