训练算力泄露了,参数量就算得出来吗?算得出来,但前提是你得先假设训练 token 数——而那个假设几乎决定了答案。
前阵子流传一份微软的幻灯片,上面标着 Claude Mythos 的训练总算力:6.1×10²⁷ FLOP,95% 置信区间 5.3×10²⁷ 到 7.1×10²⁷(假设 1 像素的测量误差)。
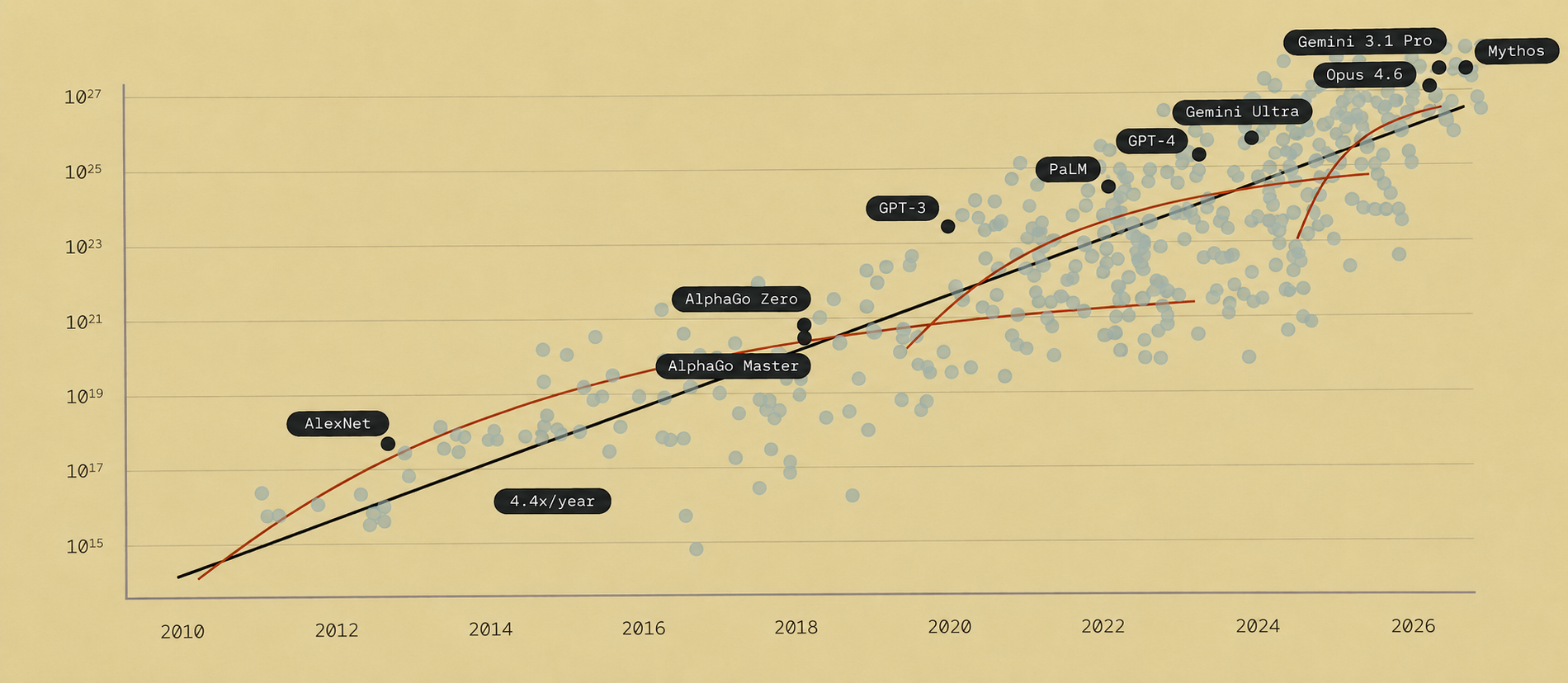
看到这个数字,所有人的第一反应都是同一个问题:那它到底多大?多少 B 参数?
这是个看似能算、其实没那么容易的问题。下面把方法拆开,顺便说清楚为什么所有公开的「参数量估计」都得打折。
一个公式把两件事连起来
训练算力和模型规模之间,有一个被反复用的粗略关系:
C ≈ 6NDC 是训练总 FLOP,N 是参数量,D 是训练 token 数。它来自「前向 + 反向每 token 大约 6N 次浮点运算」的近似,是 Chinchilla 那篇 scaling 论文的分析基础。
问题立刻就来了:一个方程,两个未知数(N 和 D)。光知道 C,解不出 N。
你必须先假设 token 数
这是整件事最容易踩的坑。要拿到一个 N,必须再补一个对 D 的假设。最常见的是 Chinchilla 的 compute-optimal 口径:数据量大约是参数量的 20 倍,D ≈ 20N。代回去:
N ≈ √(C/120)于是 6.1×10²⁷ FLOP → √(6.1e27/120) ≈ 7.1T 参数,对应约 143T token。
但要注意这个「7.1T」到底是什么:它不是真实参数量,而是**「如果这个模型按 Chinchilla 意义上算力最优的方式、且是 dense 架构训练,它该有多大」**。真实模型如果是 MoE、或者训练 token 远多于 20 倍参数,这个数就和现实差一截。
套在历史模型上看看准不准
把同一套 √(C/120) 往几个公开模型上套,能看出这个口径到底有多靠谱:
| 图中模型 | 图上训练 FLOP 粗读 | 折算参数量 (B) | 备注 |
|---|---|---|---|
| AlexNet | ~4.5×10¹⁷ | ~0.06B | 公开论文实际约 60M 参数,和折算值基本对上。(NeurIPS 会议录) |
| AlphaGo Master | ~3×10²⁰ | ~1.6B | RL/搜索系统,不太适合直接和 LLM 的 “B 参数” 类比。 |
| AlphaGo Zero | ~7×10²⁰ | ~2.4B | 同上,更多是”按 FLOP 硬折算”的量级。 |
| GPT-3 | ~3.2×10²³ | ~52B | 公开实际是 175B,因为 GPT-3 不是 Chinchilla-optimal 口径训练。(arXiv) |
| PaLM | ~3.8×10²⁴ | ~180B | 公开实际是 540B,同样比 compute-optimal 折算值大。(Google Research) |
| GPT-4 | ~2.8×10²⁵ | ~480B | 官方没公开模型大小/训练 compute 等细节。(OpenAI) |
| Gemini Ultra | ~8×10²⁵ | ~810B | 参数量未公开。(crfm.stanford.edu) |
| Claude Opus 4.6 | ~2.0×10²⁷ | ~4,100B,即 ~4.1T | Anthropic 未公开模型大小/架构细节。(crfm.stanford.edu) |
| Gemini 3.1 Pro | ~6×10²⁷ | ~7,100B,即 ~7.1T | 顶部点很挤,像素读数误差会比较大。 |
| Claude Mythos | 6.1×10²⁷ | ~7,130B,即 ~7.1T | 按 95% CI:约 6.6T–7.7T。 |
规律很清楚:老一点的、没按 compute-optimal 训练的模型,折算值会系统性偏小。 反过来说,如果 Mythos / Gemini 3.1 Pro 这类前沿模型也是「过训练」(train on more tokens than optimal),那 7.1T 同样是高估了等效参数——真实激活参数可能更小。
换个 token 假设,答案差一倍
最能说明问题的,是固定 C、只改 D 时 N 怎么变。以 Mythos 的 6.1×10²⁷ 为例,用 N = C/(6D):
| 训练 token 假设 | 折算参数量 |
|---|---|
| 100T | 10.2T |
| 143T(Chinchilla) | 7.1T |
| 150T | 6.8T |
| 200T | 5.1T |
训练 token 从 100T 涨到 200T,参数量估计直接砍半。而前沿实验室现在普遍倾向「小底座喂超多数据」(过训练:宁可一次性多花训练算力,换更低的每次推理成本),所以真实 N 很可能在偏小的那一头。
一个被打脸的黑箱估计法
上面是从 FLOP 这一头反推参数量。还有另一类黑箱估计,干脆不碰 FLOP——最近有个叫 IKP(Incompressible Knowledge Probes)的方法:用一批事实性问题校准开源模型,再用「事实容量」反推闭源模型的参数。它原始结果把 GPT-5.5 放到了 [3.2T, 28.7T],网传中心约 9.7T。
但很快有人复核,发现结论对方法细节极度敏感——换一套校准方式,GPT-5.5 就掉到 1458B,90% 置信区间 [256B, 8311B],GPT-5.5 Pro 是 1471B。中心值从 9.7T 缩到 1.5T,差了一个量级。作者自己也强调,这个单点不该当成确信的真实参数量。
这件事的教训比数字本身重要:黑箱估计的「点估计」几乎不可信,可信的只有量级和区间。
我的判断
GPT-5.5 这类没人公开的模型,我会这么报:
- 中心估计 ~1.5T
- 现实区间 1T–4T
- 9.7T 是激进上沿,不是中心值
这个区间仍然很大,但比一个精确到个位数的假数字诚实得多。
一句话
6.1×10²⁷ FLOP 不唯一对应任何参数量。在 Chinchilla 口径下它约等于 7.1T,但只要训练 token 数换个假设,答案就在 5T–10T 之间漂。
下次看到「某模型算力泄露,算出 XX 万亿参数」,可以直接问三个问题:这个 XX 是按什么 token 假设算的?模型是 dense 还是 MoE?是 compute-optimal 还是过训练?三个里只要有一个不同,XX 就不是同一个量。大多数这类标题里的精确数字,都经不起这三个问题。
参考资料:Chinchilla / Compute-Optimal(Princeton COS 597G 课件) · IKP 原论文 · IKP 复核(LessWrong) · CRFM 模型透明度报告